最終プロジェクト
最終課題について
最終課題発表会の日程は8/30です。
それまでに各チームで以下のタスクを行うコードを準備してください。 また、チームでGitHubにリポジトリを作成し、準備したコードをアップロードしてください。
すべてのタスクを完璧に実装しようとすると少し大変なので、まずは、ヒントを参考に「はじめの一歩」を実装するのを目指しましょう。
ルールの質問、実装のやり方などわからないことは #q-roomba で質問お願いします! また、角川でも質問対応デーを設ける予定です。
ルール
1チームずつTask1とTask2の2つのタスクを行い、その合計点を競います。
それぞれのタスクは図の環境で行われます。(角川にある環境です。)
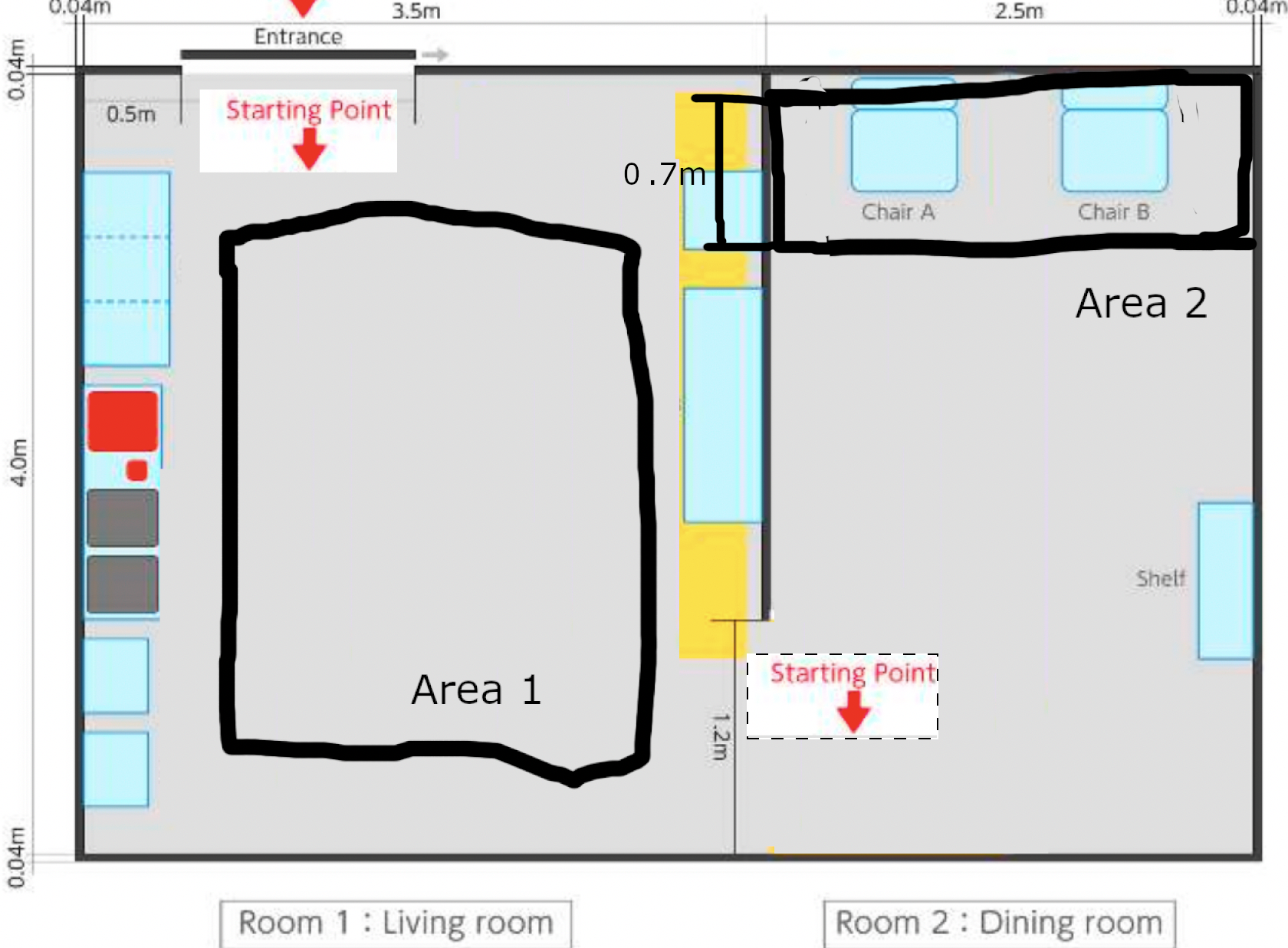
それぞれのTaskのStaring Pointではルンバの自己位置を合わせることはできますが、一度ルンバが動き始めたら人が介入することができないことに注意してください。(リスタートを除く)
Task1
ルール
Task1では、3分の制限時間の間で、Room1のStarting Pointからルンバを自律移動させ、Area1内に落ちている5つの物体を避けながらRoom2へと移動することが目標になります。
途中でロボットが停止した場合などは再びStarting Pointからリスタートすることができます。
また、Area1内に落ちている5つの物体を検出し、正しく分類することで追加ポイントを獲得することができます。
タスク終了時にArea1内で出てきた物体の名前をターミナルに表示してください。
また、5つの物体は以下の8個の物体からランダムに選択されます。

物体の名前は左から順に
- chips can
- mini soccor ball
- rubic cube
- banana
- apple
- strawberry
- toy plane
- wood block です。
実際に使用する物体は角川に置いてあります。
採点基準
ゴール得点と物体検出得点それぞれ100点満点です。また、ゴール得点と物体検出得点それぞれの得点が負になることはありません。
ゴール得点内訳(100点満点)
制限時間以内にゴール(Room2)に辿り着けたら100点、物体に衝突するたびに物体ごとに-20点、加えて、ロボットをStarting Pointからリスタートする度に-10点
物体検出得点内訳(100点満点)
検出結果の分類結果が正しければ物体ごとに+20点、間違っていたら-20点
ヒント
はじめの一歩
- Task1はまず、ゴールへ移動するコードを作成することを目標にしましょう (スクリプトでナビゲーションを行うためのヒント参照)
- 余裕があれば、他のヒントを参照して高得点を目指していきましょう
スクリプトでナビゲーションを行うためのヒント
- スクリプトでナビゲーションを行うコード(https://matsuolab.github.io/roomba_hack_course/course/chap6/service-actionlib/ の演習)を参考に、指定した位置へ移動するコードを書いてみましょう
障害物を避けながらnavigationするためのヒント
- 物体検出器を改善するためのヒントおよび https://matsuolab.github.io/roomba_hack_course/course/chap6/service-actionlib/ の総合課題を参照し、課題物体を検出し、それをコストマップに追加することで障害物を避けるコードを書いてみましょう
より正確な自己位置推定を行うためのヒント
- amclのパラメータ調整 (参考: https://matsuolab.github.io/roomba_hack_course/course/chap4/localization/ の演習)をしてみましょう
- gmappingを用いてより正確な地図を作成 (参考: https://matsuolab.github.io/roomba_hack_course/course/chap4/localization/ の演習)してみましょう
- emcl(https://github.com/ryuichiueda/emcl)等の異なる自己位置推定アルゴリズムを使ってみましょう
- Lidarの位置を合わせをより正確に(https://github.com/matsuolab/roomba_hack/blob/master/catkin_ws/src/roomba/roomba_description/urdf/roomba.urdf.xacro を編集)合わせてみましょう
物体検出器を改善するためのヒント
- 自作データを用いて既存モデルの学習 (参考: https://eng-memo.info/blog/yolo-original-dataset/) を行ってみましょう
Task2
ルール
Task2では、3分の制限時間の間で、Room2のStarting Pointからルンバを自律移動させ、Area2にいる2人の人のうち、手を振っている人の前で停止することが目標になります。
また、2人の人がArea2にある2つの椅子に座っており、そのうち一方のみが手を振っていることが保証されています。
途中でロボットが停止した場合などは再びStarting Pointからリスタートすることができます。
採点基準
Task2全体で150点満点です、また、Task2の得点が負になることはありません。
時間以内にいずれかの人の前に移動が成功し、その場で停止する(人の50cm以内に到達する)+70点
上に加え、正しい人(手を振っている人)の前に移動が成功する+80点
加えて、ロボットをStarting Pointからリスタートする度に-10点
ヒント
はじめの一歩
- Task2はまず、人を検出して移動するコードを作成することを目標にしましょう (人を検出して移動するためのヒント参照)
- 余裕があれば手を振っている人の検出にチャレンジしてみましょう
人を検出して移動するためのヒント
- 人を検出する部分については三次元画像処理で扱ったYOLOv3で検出することができます
- 検出した結果に対応する深度画像から距離を取得することで、人の近くへ移動するコードを書くことができます
- (参考: https://matsuolab.github.io/roomba_hack_course/course/chap5/three-dimensions/ のdetection_distance.py)
- さらに余裕があれば、深度画像を点群等に変換するとより正確な移動が可能になります
手を振っている人の検出
- 学習済みのKeypoint R-CNNを用いることで人間の手や腕の位置などのキーポイントを推定することができます。
技術プレゼンについて
最終競技会のために開発した技術について、発表会でプレゼンを行います。
プレゼンの評価方法は RoboCup@Home のルール に基づいています(7.2 Evaluating Juries for Final Demonstrations 参照)。
評価項目は、internal jury と external jury で異なっています。
- internal jury(大会参加者による相互評価)
- Efficacy/elegance of the solution
- タスクの解決策の効果の高さ / エレガンスさ
- Difficulty of the overall demonstration
- 全体的な技術的難易度の高さ
- Efficacy/elegance of the solution
- external jury(大会運営者による外部評価)
- Originality and presentation (story-telling is to be rewarded)
- オリジナリティ、プレゼンの完成度
- Elegance/success of overall demonstration
- 全体的なエレガンスさ、達成度
- Originality and presentation (story-telling is to be rewarded)
各項目 10 点満点で評価し、internal, external それぞれの平均値の合計を得点とします。